-
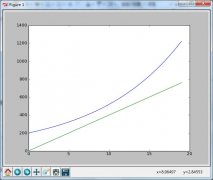 【matplotlib】Python画图神器初体验
日期:2017-04-27 22:25:22
点击:424
【matplotlib】Python画图神器初体验
日期:2017-04-27 22:25:22
点击:424
写matplotlib这个的demo源于在网上看到一个有意思的面试题,面试题是这样的:“在北京某地段,一位软件工程师看中了一套房子,售价是200万。不过,以目前工程师的收入还买不起,只...
-
 【pyahocorasick】python处理违禁词
日期:2017-03-23 21:34:15
点击:2818
【pyahocorasick】python处理违禁词
日期:2017-03-23 21:34:15
点击:2818
今天二营长有个需求,需要对百万级别的关键词进行违禁词过滤,每次都找研发兄弟跑,人家估计不耐烦了,啪...把程序扔给我了,让我自己跑,看到脚本的当时我是崩溃的,这TM的是...
-
Python多线程抓豆瓣图书
日期:2016-12-29 21:18:52
点击:387
今天二营长又有了新的需求,需要抓豆瓣的图书信息。于是又拼了个轮子。 #coding:utf-8importrequests,re,time,string,random,sys,threadingfrombs4importBeautifulSoupfrommultiprocessing.dummyimportPoolasThreadPoolrelo...
-
【神器】Python批量生成sitemap
日期:2016-12-24 14:40:42
点击:1290
这周二营长SEO有个需求,需要批量生成sitemap,由于百度站长平台对单个sitemap文件的url数量的限制,当url数量大于50000时,需要生成新的文件,特此写了个python脚本,工作日时间紧,当时...
-
Python计数去重代码
日期:2016-12-11 16:03:23
点击:650
前几天有个需求,在百度上抓了一批serp的url,需求是对这些url进行提取每个url的域名、然后对域名计数去重,提取每个url的域名好弄,有现成的函数能用,就是这个计数去重,其实在自...
-
 Python爬虫浏览器useragent大全
日期:2016-12-10 22:19:52
点击:861
Python爬虫浏览器useragent大全
日期:2016-12-10 22:19:52
点击:861
平常在写Python爬虫的时候经常用到一些反爬策略,比如在请求时加上cookie、浏览器useragent切换、使用ip代理等,遇到一些小的站点还好,不用什么反爬策略就能顺利的把想要的数据抓下...
-
 Python爬虫策略的重要性
日期:2016-12-07 21:20:20
点击:302
Python爬虫策略的重要性
日期:2016-12-07 21:20:20
点击:302
会写点Python爬虫总要爬点东西来展示下自己(装装逼),今天说说爬虫策略的重要性,写爬虫没有策略不行,在确定目标url以后爬取、分析、存储的策略要大概先在自己脑瓜儿里过一遍...
-
Python爬虫代理ip
日期:2016-12-07 14:21:31
点击:318
文章可以分为几个部分:代理IP从何而来?如何保证代理质量?采集回来的代理如何存储?如何让爬虫更简单的使用这些代理? 1、代理IP从何而来?刚自学爬虫的时候没有代理IP就去西...
-
Python网络爬虫实战项目代码大全
日期:2016-12-06 23:11:48
点击:296
[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。 https://github.com/Chyroc/WechatSogou [...
-
 为什么选Python来辅助SEO?
日期:2016-12-01 20:24:45
点击:797
为什么选Python来辅助SEO?
日期:2016-12-01 20:24:45
点击:797
python在SEO上面还是有很大的帮助,不需要达到专业的python开发人员的水平,能利用python这个工具实现自己目的就足以。 先说下为啥用python而不用其他的编程语言: 1、当我们有某些web数...